OpemMPIのベンチマーク1 [MPI]
OpenMPIのベンチマークをとってみる。
構成
Node0) Indel Core2Quad Q9550/8G DDR2 800 RAM/Fedora 11
Node1) Indel Core2Quad Q9450/8G DDR2 800 RAM/Ubuntu 9.04
2つのノードは1Gbbs対応のHUB(D-link/DGS-2208)で接続。
1)同じホスト間(つまり同じマシン内でのスレッド間通信)
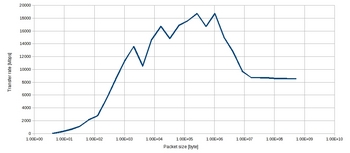
2)異なるホスト間
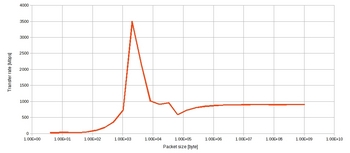
<考察>
1)は基本的にスレッド間通信なので、単純なメモリコピー。
測定マシンがHost1で、DDR2 800、デュアルチャンネルを使っているので、メモリ帯域は最大12.8G/s。TCPの通信によるオーバーヘッドやら何やらで、1/12位に落ちるようだ。
真ん中あたりは、CPUIキャッシュでうまくヒットしているのかもしれない。
2)パケットサイズが大きくなると、シーケンシャルになるので、概ね1GEtherの理論値の90%位出ている。小さいサイズになるとOS側のメモリキャッシュの影響か、1Gbpsを超える物がある。このあたりは測定プログラムを検討する必要がある。
以上ざっくりだが、TCPの通信のためか、CPU使用率が非常に高くなる。
現状ブロッキング通信なので、単純にビジーウェイトで待っているだけなのかもしれない。
HUBの影響を排除使用と思って、ピアツーピアで接続しようとしたら、ゲートウェイの設定を変更しなければならないので、今は面倒だからやっていない。そのうちやろう。
非ブロッキング通信Isend/Irecvの場合も検証していく予定
構成
Node0) Indel Core2Quad Q9550/8G DDR2 800 RAM/Fedora 11
Node1) Indel Core2Quad Q9450/8G DDR2 800 RAM/Ubuntu 9.04
2つのノードは1Gbbs対応のHUB(D-link/DGS-2208)で接続。
1)同じホスト間(つまり同じマシン内でのスレッド間通信)
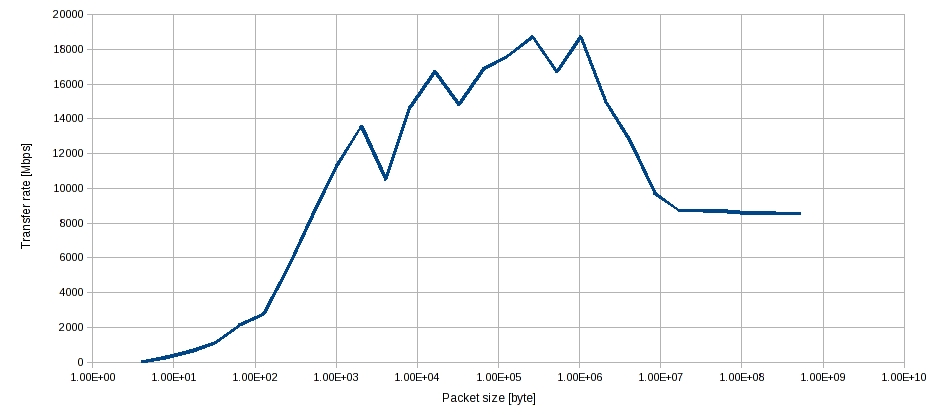
2)異なるホスト間
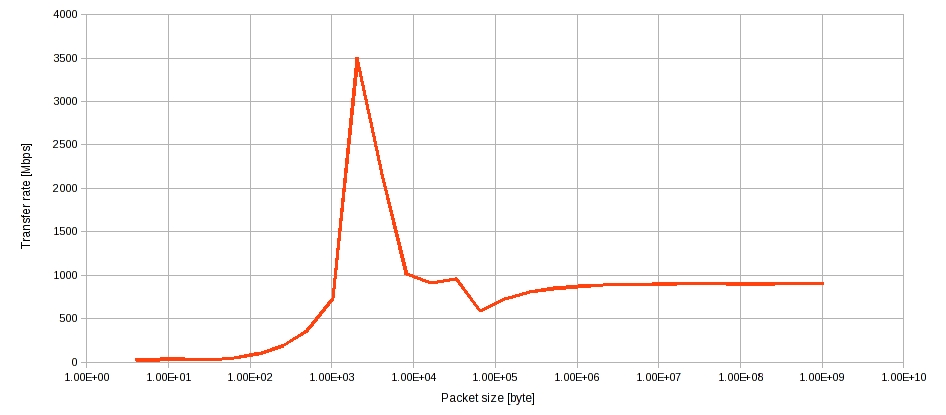
<考察>
1)は基本的にスレッド間通信なので、単純なメモリコピー。
測定マシンがHost1で、DDR2 800、デュアルチャンネルを使っているので、メモリ帯域は最大12.8G/s。TCPの通信によるオーバーヘッドやら何やらで、1/12位に落ちるようだ。
真ん中あたりは、CPUIキャッシュでうまくヒットしているのかもしれない。
2)パケットサイズが大きくなると、シーケンシャルになるので、概ね1GEtherの理論値の90%位出ている。小さいサイズになるとOS側のメモリキャッシュの影響か、1Gbpsを超える物がある。このあたりは測定プログラムを検討する必要がある。
以上ざっくりだが、TCPの通信のためか、CPU使用率が非常に高くなる。
現状ブロッキング通信なので、単純にビジーウェイトで待っているだけなのかもしれない。
HUBの影響を排除使用と思って、ピアツーピアで接続しようとしたら、ゲートウェイの設定を変更しなければならないので、今は面倒だからやっていない。そのうちやろう。
非ブロッキング通信Isend/Irecvの場合も検証していく予定
2009-09-14 23:20
nice!(0)
コメント(0)
トラックバック(0)




コメント 0